The Data Modeling Framework
On the surface, many systems look functional. Data is connected, reports are being built, and numbers are showing up where they are supposed to. Underneath, however, the structure is fragile. Every new data source creates more complexity, every change requires more work, and over time the system becomes something only one or two technical people can even understand, let alone maintain. That is not a scaling problem. It is a modeling problem.
The root of it usually comes down to how transformation is handled. Most teams treat transformation as a cleanup step. They remove errors, rename a few columns, perhaps standardize some formats, and move on. The data looks cleaner, but it is not actually structured. It is just slightly more organized chaos. The next step is to try to combine everything, and this is where things begin to unravel. Data gets appended, relationships get layered on top, and tables start connecting in ways that were never originally designed. The result is a tangled model that technically works, but only under very specific conditions. Change one thing and something else breaks. Add a new source and an entirely new set of logic is needed to make it fit. This is where most systems begin to collapse under their own weight. The issue is not the tools. It is that the data was never shaped into something that could scale.
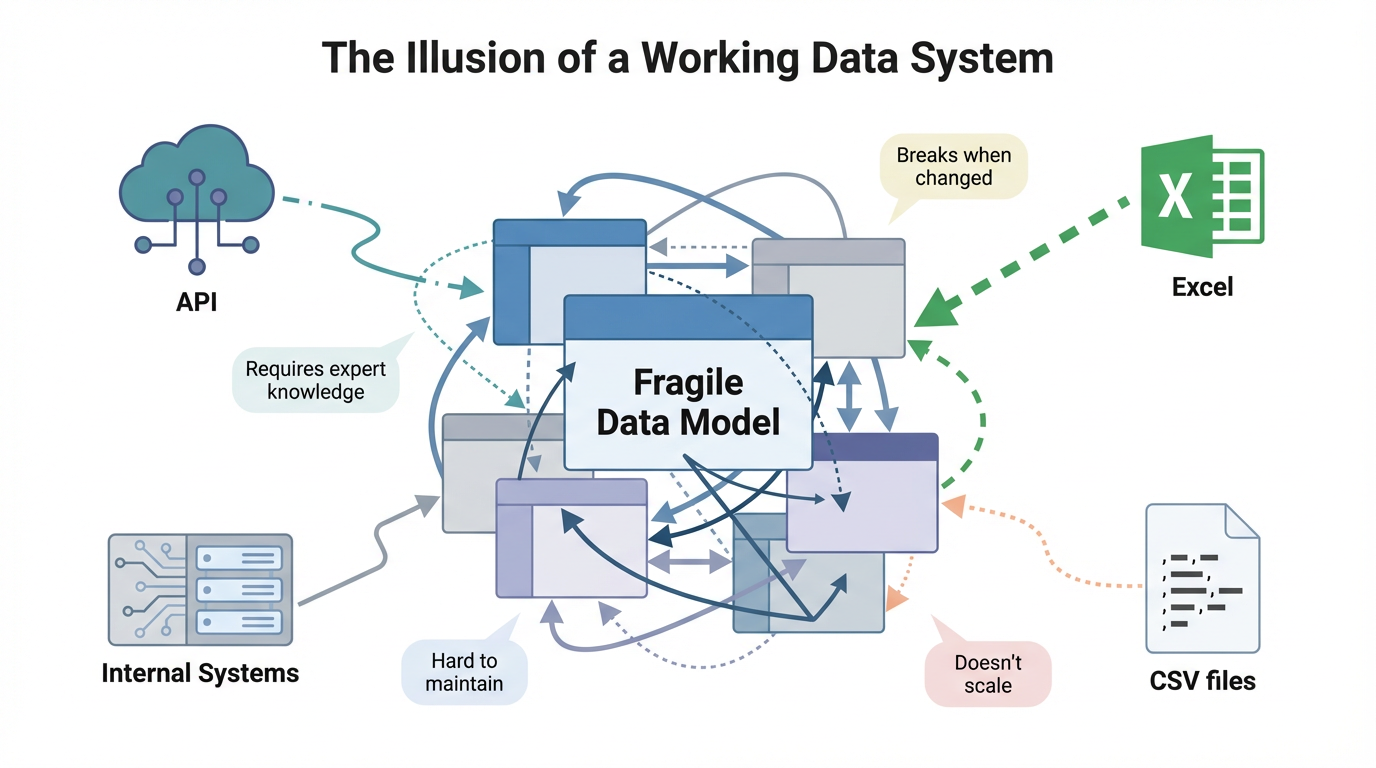
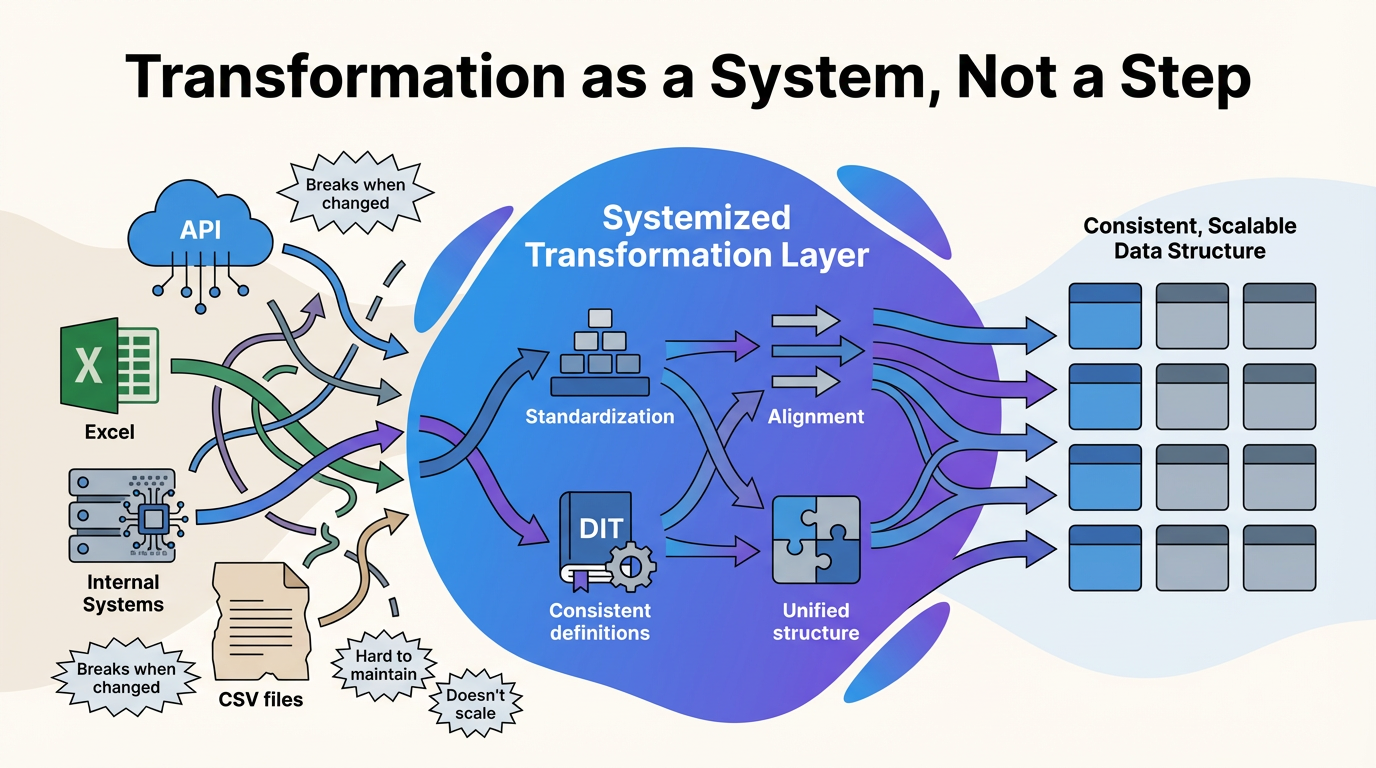
A strong data model does not come from cleaning data. It comes from systematizing how data is transformed before it ever reaches the model. Transformation is where structure is created. It is where different sources, no matter how inconsistent, are reshaped into a consistent format that can be used across the entire system. That is the difference between stacking data and actually integrating it. When transformation is done correctly, each data source becomes a compatible building block. It does not matter if the source is an API, a spreadsheet, or an internal system. By the time it reaches the model, it follows the same structure, the same definitions, and the same level of detail. That is what allows everything to connect cleanly. Without that foundation, the work is not building a model; it is constantly patching one together.
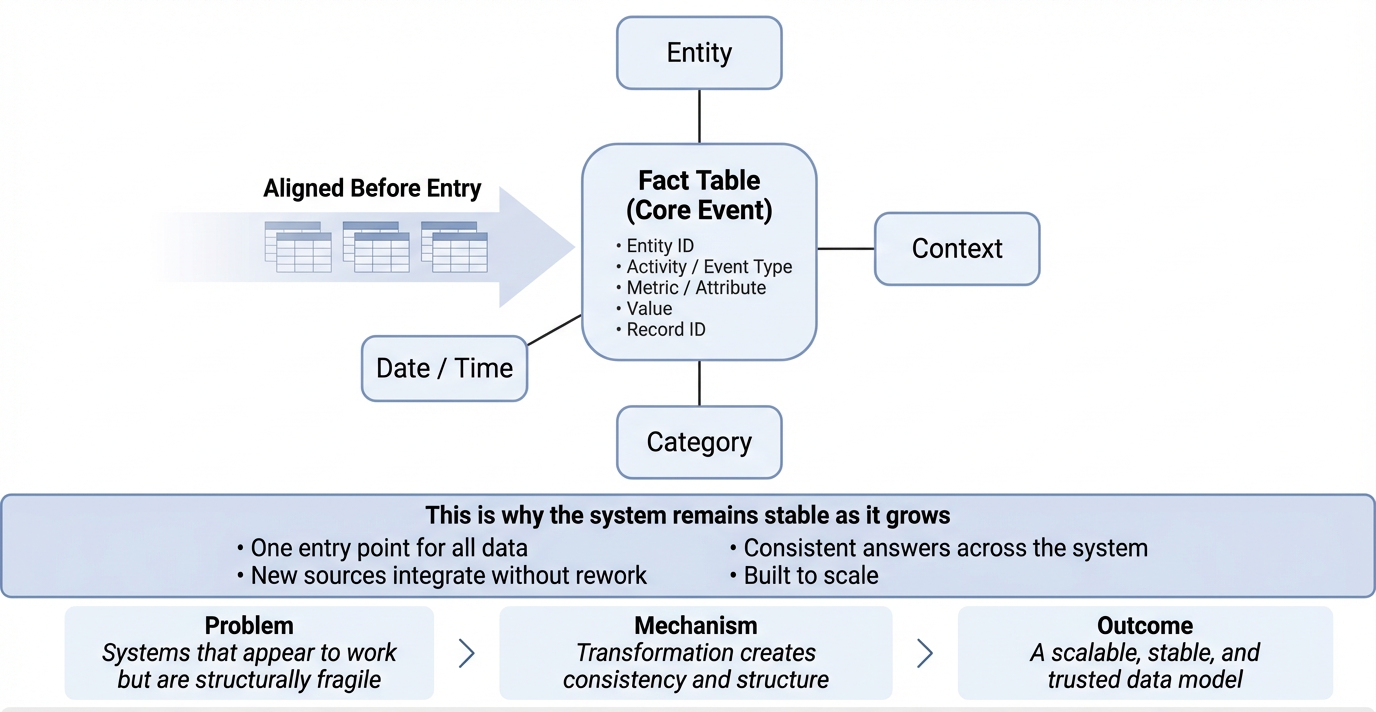
The goal is not to make data usable in isolation. The goal is to make it usable together, and this is where modeling takes shape. At the center of a strong system is a well-defined fact table. In a sports performance context, that might be something like a performance set, a single table that captures the core event at the right level of detail. Player ID, exercise, attribute, score, and rep ID all funnel into that structure. It does not matter how many sources the data comes from or how different they are initially. Once they pass through the transformation process, they land in the same place and in the same format. That is where scale comes from. Instead of building new logic every time new data is introduced, the system absorbs it. Terabytes of data can flow through one structured entry point because everything has been aligned before it arrives.
Around that fact table, dimension tables are built to provide context. Athlete, date, exercise, and others depending on the environment all define relationships and allow users to slice, filter, and understand the data without needing to know how it was constructed. This is what a clean star schema actually delivers: not just performance from a technical standpoint, but usability. The real test of a model is not whether it works for the person who built it. It is whether it works for the people who did not. If a model requires deep technical knowledge to use, it is already limited. It will not scale across an organization, it will not survive a handoff, and it will not empower non-technical users to interact with it in tools like Excel or Power BI.
A well-modeled dataset becomes something entirely different. It becomes a foundation. Analysts can build on it, coaches can explore it, and decision-makers can trust it. Because the structure is consistent, the answers do not change depending on where someone looks. This is also where governance becomes much easier. When the model is clean, access can be controlled at a logical level. Row-level security can be applied without breaking relationships, user inputs can be incorporated into dimension tables without disrupting the entire system, and everything behaves predictably. None of that is possible in a poorly structured model, and most poorly structured models are not the result of bad intent. They are the result of skipping the hard part, which is designing a transformation process that forces consistency across every data source.
Once that process is in place, everything downstream becomes easier. Modeling becomes cleaner, reporting becomes more reliable, and iteration becomes manageable instead of disruptive. Without it, the work is entirely reactive. With it, the work produces something that can actually last. Data modeling is not about tables and relationships. It is about creating a structure that allows data to scale, to be understood, and to be trusted across an entire organization. That only happens when transformation is treated as a system rather than a step, because if data does not come in structured, it will not become structured later. Without structure, there is no model. There is only more data.
DANNY DAVIS · Executive insights